Raft consensus explanation
- Raft is an algorithm for implementing a distributed consensus
- Equivalent to Paxos (another well-known consensus algorithm) in fault-tolerance and performance
- The difference from Paxos: decomposed into relatively independent subproblems, and it cleanly addresses all major pieces

What is distributed consensus
- Distributed systems need to store same data on many machines (called nodes)
- Consensus is a fundamental problem in fault-tolerant distributed systems that adreses the question how all nodes should agree about some data value (what value is reliable).
- typical consensus algorithms make progress when majority of their servers are available (e.g.
3of5) - when majority unavailable, cluster stop making progress (but will never return an incorrect result).
Raft Leader election (brief)
Each node in system can be in 3 states:
followercandidateleader
By default all nodes are followers. If follower doesn't hear from a leader for some time then it becomes candidate and requests votes from other nodes.
- Nodes reply with their vote
- Candidate becomes the leader if gets a majority (
3/5or3of4, but not2of4) of nodes (available or all? how node know about the total amount?) - Now all changes go through leader
Raft Log Replication (brief)
Each change added as an entry in the node log.
- When an application adds the entry to the leader, it is yet not committed (will not update leader node value).
- To commit, leader node first replicates state to follower nodes and waits for responses from majority of nodes that they have written the entry
- Only now entry is committed and node state is 5
- After that leader notifies followers that entry is committed (followers also change values)
- Now cluster has come to consensus
Raft Leader election details
election timeout Time that follower wait until becoming the candidate. Randomized between 150ms and 300ms.
- After becoming candidate node increases election term (some sequential number, e.g. 1,2,3). By default term is
0.
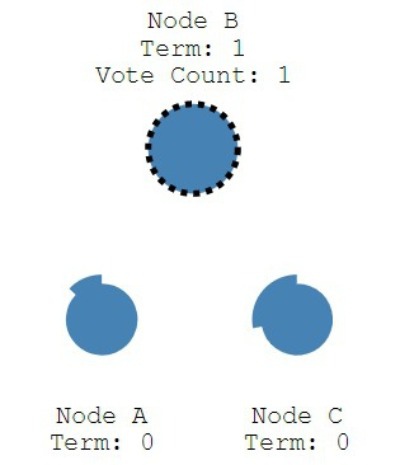
- It counts 1 vote (votes for itself) and sends request vote.
- If receiving node hasn't voted yet in this term number, it votes for it, accepts term and resets election timeout
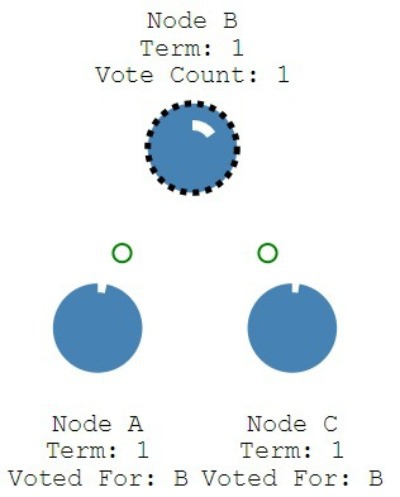
- After becoming leader it sends Append Entries message (each Heartbeat timeout). When node received Append Entries it resets own election timeout and send response.
- Requiring MAJORITY OF VOTES GUARANTEES THAT ONLY ONE LEADER can be elected per TERM
If 2 nodes becoming candidate at same time split vote may occur (both voted for itself in current term, and have equal votes from other, so no one has MAJORITY !), all will wait next term
Partitioning
If network partitioned:
Client cant write 3 because majorite not written:
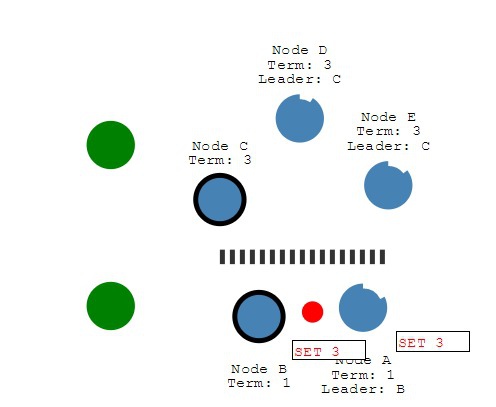
Another client can write:
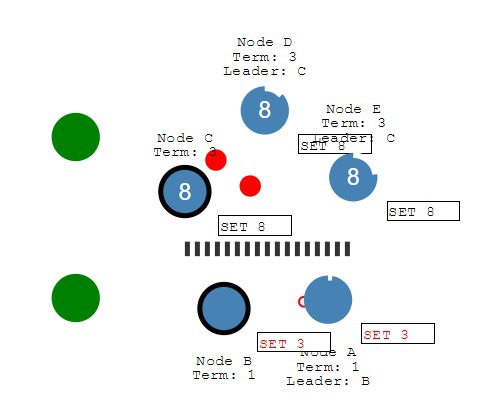
After merging the partitioned network, leader B will see higher election term and step down (A and B will rollback uncommitted entries and match leader's log
Tip based on http://thesecretlivesofdata.com/raft/
Raft Paper raft.pdf
Raft site: https://raft.github.io/