AWS batch: use cloud power for batch processing [Simple example]
Howdy, I am Ivan Borshchov, a CTO at Devforth software development company, and we have been smoothly using AWS Batch in production for a year.
Here I will provide all needed information to start using AWS batch tool in a matter of hours or even minutes without reading the docs. Also, I will explain why AWS Batch is a great deal comparing to non-cloud solutions. As a bonus, we give you an example in Github Repository with fully automated deployment.
But before using any tool you have to know very well in which cases should you select it to make sure you are not wasting time and money, so the next section will help you understand a niche of batch processing.
Batch processing for IO and Computing jobs
Batch processing task means that you need to run multiple jobs in parallel to speed up the achievement of the final result. When we consider any long-running jobs it is very important to distinguish two types of them:
- IO-heavy
- Computing-heavy
The first type contains tasks like – downloading or uploading something from different servers, for example, media streams or files, sending emails, notifications, performing millions of HTTP or REST API requests to crawl websites. These all are IO operations. To process them in batch and minimize runtime mode you can use ONE CPU on ONE MACHINE, and optimize time by just using special techniques like async-programming (you might hear related words like async/await), or old-school less efficient approach using Threads. You don't need several machines or CPUs to make it faster, it would be a stupid usage of resources. Here CPU only initializes IO operation, and does it pretty quickly, other time CPU is free and can start next IO operation.
A general approach to boost a big amount of such IO tasks is to convert sequential requests into parallel:
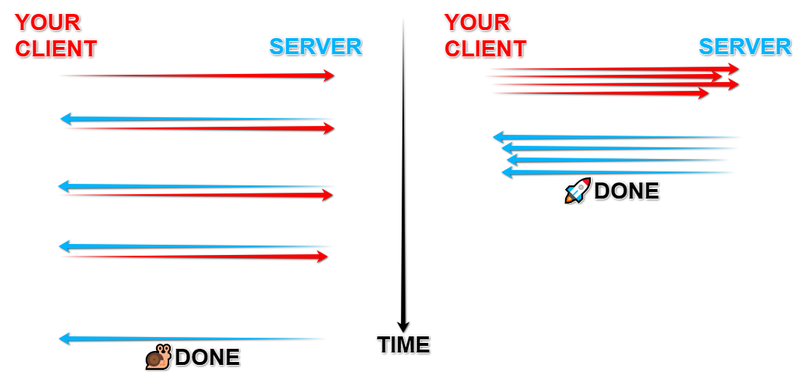
The picture above is very simple and you might think it is obvious, but unfortunately, most of the programs in our world use the left snail way. Why? Because it is a natural way in the majority of programming languages and most frameworks. Async programming creates new extra-challenges and requires stronger developer qualifications.
The Computing-heavy type is different. Here you can't just start several jobs on one CPU in parallel because one job will fully utilize one CPU core. You can involve several cores but you are still limited. This approach is needed for all mathematical-related algorithms – neural networks, machine learning, crypto-miners, some mathematical brute-force algorithms for example Monte Carlo Method.
Monte Carlo Method is a very smart and graceful brutal approach. In two words: when you have some function of some number of arguments
y = f(x1, x2, x3, ... xN)and you want to find values of(x1, x2, x3, ... xN)on which you receive the best value ofy(like the best profit), you can just change each argument randomly (within some range fromxI_mintoxI_max) and brutally calculate function value unless you will find bestyvalue. This method is simple and awesome but to get really good results you need to executeffunction a lot of times, and with an increasing number of arguments, this requirement grows dramatically.
Here, to save time, you need a lot of CPU cores, which you can get only on hundreds or even a thousand machines. Building such clusters by yourself would be incredibly expansive. So here clouds like AWS make a turn!
Complex tasks which are both IO heavy and CPU heavy still require batch
For example, you want to make end-to-end stress testing for your website. End-to-end means that you want to simulate users as reliable as possible. So you decided to run a puppeteer to load your frontend and emulate clicking. So you created a bot that follows some infinite scenario in the real Chromium-based browser controlled by a puppeteer and now needs to increase the number of such bots. Seams like interaction with the server are done only via a network, so it is an IO task.
If you would simulate users' behavior with a pure request then probably you would be able to run a lot of users on one PC just using asyncio techniques. But here the situation is different: you have a browser that involves CPU a lot and uses your RAM. So how many resources does your website consumes when it opened in one Chromiums tab?
So yes, we used AWS Batch for this task very smoothly.
Why cloud is a great deal for batch processing
Each cloud by definition has a lot of free, temporary unrented machines. In AWS it is EC2 instances. And the cloud provider can earn much more if he will rent them to you to execute your batch processing jobs. That is why they created AWS Batch.
AWS Batch itself is just a scheduler and it is free – you pay only for EC2 instances runtime (on hourly bases).
The main great advantage which we receive, that we can borrow a really big piece of the cloud (N CPU cores) for a short time T and pay the same price if we would rent 1 CPU and spend N * T. So AWS Batch allows us to make the job faster with the same price, just because they have free unused resources in a cloud. Also, you have to know that there are cheaper EC2 spot instances which work great with AWS Batch.
BTW I am not talking that cloud is a cheapest way if you need some VPS or dedicated server – you will be able to find better deal by working with some less-popular hosting providers on the market, but I have doubts that you will be able to use their resources in a way which AWS Batch provides.
Prerequerements to use multi-processor batch computing
It is very important to do one small check before starting implementing batch processing for your task: make sure your job is compatible with parallelism. This is easy to explain in terms of programming routines. You can state that your long task is compatible with parallelism if you could divide it by two and more smaller routines on which input does not depend on each other results.

Not every task supports parallelism. But in most cases, you can find a parts even in hard algorithms that could be parallelized.
A simple task to show you how to use AWS Batch
Here at Hinty, we aim to give you easy hints which will lead you to a real result. Now we will run a simple Batch job that finds MD5 hash collision. Our task is next:
We have some md5 hash e80b5017098950fc58aad83c8c14978e, so we know it was created by calling:
md5(x) -> e80b5017098950fc58aad83c8c14978e
We want to find any x which returns the same hash. A lot of websites coded without frameworks used pure md5 hash without salt to store the password, so if you accidentally got such hash somewhere, you can try to find the value of the user password for example to try it on other websites with same username (on other sites you even don't care about algorithm if you will be able to find a password). But we don't recommend you to use it in real life 😜
Create an AWS Account
If you don't have an AWS account yet you need to create it, then you have to create a user with programmatic access. How to create account and user for API access
Then, again you don't have it, you need to create an AWS Profile. Open a terminal and type:
nano ~/.aws/credentials
So you opened nono text edit. Now insert next:
| [batcher] | |
| aws_access_key_id = xx | |
| aws_secret_access_key = yyy |
- Replace
xxwith actual value ofaws_access_key_idfrom downloaded.csvfile e.g.AKIAQO7PVZSAHEXG45 - Replace
yyywith actual value ofaws_secret_access_keyfrom file.
It will work on Linux and Mac environment, on Windows, we recommend using WSL 2
To run our example you need to install docker-ce on your machine. For windows check here: Docker in Windows WSL2. For Linux Ubuntu it could be done with the next commands:
| sudo apt-get update | |
| sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common | |
| curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - | |
| sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/debian $(lsb_release -cs) stable" | |
| sudo apt-get update | |
| sudo apt-get install docker-ce docker-ce-cli containerd.io | |
| sudo systemctl enable docker | |
| sudo systemctl start docker |
Also, you need an aws cli and NodeJS + npm installed.
MD5 brute-forcing on AWS Batch
Our algorithm is pretty simple - we will try to iterate over all combinations of common alphabet characters and calculate md5 for each combination. Obviously, it is a computing-heavy operation with a great ability to parallelize (because we can quickly generate all combinations and they are independent inputs).
If we are going to brute-force all combinations of characters for a password with length 6 we need to calculate ALPHABET_LENGHT ^ 6 number of hashes. If we are using alphabet with lower and upper letters and digints (0-9a-zA-Z) we need to call md5 56 billion times 😲:
62 ^ 6 = 56'800'235'584
And this is only for words with length equal to 6. If you are going to try 2-chars,3-chars,4-chars,5-char passwords also, then we need call md5 even more. When websites have minimum lenght requirement of 8 characters then you need to call md5 218'340'105'584'896.
So we will smoothly and equally split whole amount of calls between our CPU cores on different instances.
Our backend engineer crafted a great open-source example, so you can just clone it and run, and then adjust for your needs and your tasks.
Let's do it:
| git clone https://github.com/devforth/AWS-Batch-Example.git | |
| cd AWS-Batch-Example |
Now run the deploy script which will create resources needed to start a cloud:
./deploy.sh batcher us-east-1
This will cost you nothing, only when you will run the calculation script it will take real resources.
Now let's run the computing script:
node batch_md5_brute_force.js batch-example 2 7 e80b5017098950fc58aad83c8c14978e 10
This will spawn an EC2 instance required and start brute-forcing.
The format is next:
node batch_md5_brute_force.js <aws-profile> <brute-forced-min-length> <brute-forced-max-length> <hex-md5> <num-of-instances-to-use>
AWS resources involved
Now we recommend you to check the file structure. The first file to take a look at is serverless.yaml. It is a file with the description of AWS resources that will be deployed. The most important resource is AWS::Batch::ComputeEnvironment:
| SpotBatchComputeEnvironment: | |
| Type: AWS::Batch::ComputeEnvironment | |
| Properties: | |
| ComputeEnvironmentName: "spot-compute-env-${self:provider.region}" | |
| ComputeResources: | |
| DesiredvCpus: 0 | |
| InstanceRole: !Ref Ec2InstanceProfile | |
| InstanceTypes: | |
| - "c4.large" | |
| MaxvCpus: 128 | |
| MinvCpus: 0 | |
| SecurityGroupIds: | |
| - !Ref BatchSecurityGroup | |
| Subnets: | |
| - !Ref BatchSubnet | |
| AllocationStrategy: SPOT_CAPACITY_OPTIMIZED | |
| BidPercentage: 50 | |
| SpotIamFleetRole: !Ref SpotFleetRole | |
| Type: SPOT | |
| Type: MANAGED | |
| ServiceRole: !Ref BatchServiceRole | |
| State: ENABLED |
Most important settings:
Type: SPOT- we are using cheaper EC2 spot instances for computing taskInstanceTypes: "c4.large"- type of EC2 instances which will be spawned. Eachc4.largehas 2 CPU cores, and3.75 GiBof RAM onboard. In the example call, we requested 10 cores to spawn. So AWS batch will span 5 EC2 instances. You can find more types here.
Another interesting resource that you might want to tune when you will implement your task is AWS::Batch::JobDefinition. It defines what script to run in the one Job, and where to get Docker image for it.
| BatchJobDefinition: | |
| Type: "AWS::Batch::JobDefinition" | |
| Properties: | |
| ContainerProperties: | |
| Command: ["python", "md5_brute_force.py"] | |
| Environment: | |
| - Name: DYNAMO_TABLE | |
| Value: !Ref DynamoTable | |
| - Name: AWS_DEFAULT_REGION | |
| Value: ${self:provider.region} | |
| Image: !Join ["", [!Ref "AWS::AccountId", ".dkr.ecr.${self:provider.region}.amazonaws.com/", !Ref ECRRepository]] | |
| Memory: 1000 | |
| Vcpus: 1 | |
| JobDefinitionName: "job-definition-${self:provider.region}" | |
| RetryStrategy: | |
| Attempts: 1 | |
| Timeout: | |
| AttemptDurationSeconds: 300 | |
| Type: container |
Resource "AWS::ECR::Repository" is used to deliver docker images to AWS Batch tasks. This all works in a next way:
1. We build docker images in deploy.sh file and push them to ECR Registry.
2. Then our node.js script uses aws-sdk to create a job and puts it to a queue. The queue itself is deployed as a standalone resource "AWS::Batch::JobQueue".3. AWS Batch spawns the required number of EC2 instances, downloads from ECR our docker images on these instances and creates containers one by one unless it fills all CPU on EC2 machine.
4. When machines will not be needed AWS Batch will return them to the cloud
This docker approach is pretty cool because we can sheep all needed libraries inside of the docker image which might be needed for your tasks (like Numpy, Scikit-learn, TensorFlow, etc) and it will be instantly delivered to any new EC2 machine which was just fetched from the cloud💪
Another resource used is DunamoDB table AWS::DynamoDB::Table. We use it as a common store, so any task can write there a result if it will find it for our md5. The important setting is BillingMode: PAY_PER_REQUEST - so we will pay micro cents per request ($1.25 per million write requests, $0.25 per million read requests). Without this setting, we had to pay several dollars per month even if we are not using the table at all.
There is another set of resources described in YAML which are needed to spawn EC2 instances. 😟 Unfortunately, In Amazon, you have to describe and configure all your sub-cloud infrastructure by yourself which looks complex for most tasks when you just need to do some simple action. Luckily, we configured them all for you🦸♂️, probably you will never need to adjust it. Just keep these resources and fork from our GitHub template when you need to start a new AWS Batch project:
AWS::EC2::VPCGatewayAttachmentAWS::EC2::VPCAWS::EC2::SubnetRouteTableAssociationAWS::EC2::SubnetAWS::EC2::SecurityGroupAWS::EC2::RouteTableAWS::EC2::Route AWS::EC2::InternetGatewayAWS::IAM::InstanceProfile
File structure of the project:
batch_imagefolder - contains resources that are used for building Docker image that will be used by Batch jobs.batch_image/md5_brute_force.py- main algorithm that is being run by Batch jobs (started in a container).batch_md5_brute_force.js- script that is used to post Batch jobs with given parameters, waits for the Batch job to finish, and retrieves the result. Now, we suggest you run it from your PC, but then you can do it e.g. from AWS Lambda if you need to integrate AWS Batch into complex web apps.
Conclusion
AWS Batch allows you to borrow the valuable part of a cloud and use it to perform batch processing tasks. In this post, we gave an open-source repository which has a minimal set of required assets to run AWS Batch with simple computing task. If you have any questions or issues, contact us via github issues.
Be ahead of time and run your heavy computations in the cloud, and always use salt for your passwords, or even better – just always trust authorization handling to well-tested frameworks

![`img for NPM install killed without a reason [Fixed] article`](https://s.hinty.io/BrLpDos8apbS86Ds4BQWCh.png)
